
Transformer torch实现
Preparing
导包
import torch
from torch import nn
from torch import optim
from torch.utils import data as Data
import numpy as np
超参数设置
d_model = 512 # embedding size
max_len = 1024 # max length of sequence
d_ff = 2048 # feed forward neural network dimension
d_k = d_v = 64 # dimension of k (same as q) and v
n_layers = 6 # number of encoder ans decoder layers
n_heads = 8 # number of heads in multi head attention
p_drop = 0.1 # probability of dropout
- d_model: Embedding的大小.
- max_len: 输入序列的最长大小.
- d_ff: 前馈神经网络的隐藏层大小, 一般是d_model的四倍.
- d_k, d_v: 自注意力中K和V的维度, Q的维度直接用K的维度代替, 因为这二者必须始终相等.
- n_layers: Encoder和Decoder的层数.
- n_heads: 自注意力多头的头数.
- p_drop: Dropout的概率.
MASK
MASK有两种,一种是因为在数据中使用了padding, 不希望pad被加入到注意力中进行计算的Pad Mask for Attention, 还有一种是保证Decoder自回归信息不泄露的Subsequent Mask for Decoder.
在Encoder和Decoder中使用Mask的情况可能各有不同:
- 在Encoder中使用Mask, 是为了将
encoder_input中没有内容而打上PAD的部分进行Mask, 方便矩阵运算. - 在Decoder中使用Mask, 可能是在Decoder的自注意力对
decoder_input的PAD进行Mask, 也有可能是对Encoder - Decoder自注意力时对encoder_input和decoder_input的PAD进行Mask
Pad Mask for Attention
输入序列的长度各不相同,通过<PAD>填充固定长度,但需要避免对填充<PAD>字符的位置计算注意力权重,故通过mask矩阵将填充字符的位置设置为True,假设<PAD>在字典中的Index是0, 遇到输入为0直接将其标为True.
def get_attn_pad_mask(seq_q, seq_k):
"""
Padding, because of unequal in source_len and target_len.
parameters:
seq_q: [batch, seq_len]
seq_k: [batch, seq_len]
return:
mask: [batch, len_q, len_k]
"""
batch, len_q = seq_q.size()
batch, len_k = seq_k.size()
# define index of PAD is 0, if tensor equals (zero) PAD tokens
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # (batch, 1, len_k)
return pad_attn_mask.expand(batch, len_q, len_k) # (batch, len_q, len_k)
Subsequent Mask for Decoder
生成自回归(autoregressive)掩码矩阵,主要用于解码器的注意力机制中,防止模型在预测某个位置的词时,访问未来位置的词。
通过掩盖目标序列中的未来词语位置,确保解码器只能看到当前和之前的词,而不能看到将来未预测的词。这在训练自回归模型时尤为重要,使用一个上三角矩阵即可:
def get_attn_subsequent_mask(seq):
"""
Build attention mask matrix for decoder when it auto regressing.
:param seq: [batch, target_len]
:return:
subsequent_mask: [batch, target_len, target_len]
"""
attn_shape = [seq.size(0), seq.size(1), seq.size(1)] # [batch, target_len, target_len]
subsequent_mask = np.triu(np.ones(attn_shape), k=1) # [batch, target_len, target_len]
subsequent_mask = torch.from_numpy(subsequent_mask)
return subsequent_mask # [batch, target_len, target_len]
单元测试
import unittest
import torch
import numpy as np
class TestAttentionMasks(unittest.TestCase):
def test_get_attn_pad_mask(self):
from utils import get_attn_pad_mask
# 测试数据
batch_size = 2
seq_len = 5
seq_q = torch.tensor([[1, 2, 3, 4, 0], [1, 2, 0, 0, 0]])
seq_k = torch.tensor([[1, 2, 3, 4, 0], [1, 2, 0, 0, 0]])
# 调用函数
pad_mask = get_attn_pad_mask(seq_q, seq_k)
# 检查输出形状
self.assertEqual(pad_mask.shape, (batch_size, seq_len, seq_len))
# 检查mask矩阵内容
expected_mask = torch.tensor([[
[False, False, False, False, True],
[False, False, False, False, True],
[False, False, False, False, True],
[False, False, False, False, True],
[False, False, False, False, True]
], [
[False, False, True, True, True],
[False, False, True, True, True],
[False, False, True, True, True],
[False, False, True, True, True],
[False, False, True, True, True]
]], dtype=torch.bool)
self.assertTrue(torch.equal(pad_mask, expected_mask))
def test_get_attn_subsequent_mask(self):
from utils import get_attn_subsequent_mask
# 测试数据
batch_size = 2
target_len = 5
seq = torch.zeros(batch_size, target_len)
# 调用函数
subsequent_mask = get_attn_subsequent_mask(seq)
# 检查输出形状
self.assertEqual(subsequent_mask.shape, (batch_size, target_len, target_len))
# 检查mask矩阵内容
expected_mask = torch.tensor([[
[0, 1, 1, 1, 1],
[0, 0, 1, 1, 1],
[0, 0, 0, 1, 1],
[0, 0, 0, 0, 1],
[0, 0, 0, 0, 0]
], [
[0, 1, 1, 1, 1],
[0, 0, 1, 1, 1],
[0, 0, 0, 1, 1],
[0, 0, 0, 0, 1],
[0, 0, 0, 0, 0]
]], dtype=torch.float32)
# 确保subsequent_mask的值与期望值一致
self.assertTrue(torch.equal(subsequent_mask.float(), expected_mask))
if __name__ == '__main__':
unittest.main()
Positional Encoding
绝对位置编码
在Transformer中, 使用的是绝对位置编码, 用于传输给模型Self - Attention所不能传输的位置信息, 使模型在处理序列数据时能够感知到词汇的位置信息。该位置编码基于正弦和余弦函数构建,并且在不同维度上采用不同的频率来表示各个位置。
$$ PE(pos, 2i) = \sin(pos/10000^{\frac{2i}{d_{model}}}) \newline PE(pos,2i+1) =\cos(pos/10000^{\frac{2i}{d_{model}}}) $$
class PositionalEncoding(nn.Module):
def __init__(self, d_model=512, dropout=.1, max_len=1024):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
positional_encoding = torch.zeros(max_len, d_model) # [max_len, d_model]
position = torch.arange(0, max_len).float().unsqueeze(1) # [max_len, 1]
div_term = torch.exp(torch.arange(0, d_model, 2).float() *
(-torch.log(torch.Tensor([10000])) / d_model)) # [max_len / 2]
positional_encoding[:, 0::2] = torch.sin(position * div_term)
positional_encoding[:, 1::2] = torch.cos(position * div_term)
positional_encoding = positional_encoding.unsqueeze(0).transpose(0, 1) # [max_len, d_model] -> [1, max_len, d_model] -> [max_len, 1, d_model]
self.register_buffer('pe', positional_encoding)
def forward(self, x):
"""
:param x: (seq_len, batch, d_model)
"""
x = x + self.pe[:x.size(0), ...]
return self.dropout(x)
在实现代码中,计算频率尺度因子 div_term 的公式:
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(torch.tensor(10000.0)) / d_model))
这个div_term实际上等价于公式中的$10000^{-\frac{2i}{d_{model}}}$,这是通过将指数对数运算转换来实现的:
$$ 10000^{-\frac{2i}{d{model}}} = exp(-\frac{2i}{d{model}}\cdot\ln(10000)) $$
使用 torch.arange(0, d_model, 2) 生成偶数索引,通过乘以 -torch.log(torch.tensor(10000.0))/d_model 缩放,得到期望的缩放因子。
代码中这种实现方式的目的是将指数缩放逻辑直接通过 torch.exp 运算符实现,以提高数值稳定性和兼容性。这种方式与论文公式等价,但实现上使用了 torch.exp 而不是直接求 $10000^{-\frac{2i}{d{model}}}$,从而避免了在实现中频繁调用幂运算,确保计算精度并优化效率。
单元测试
class TestPositionalEncoding(unittest.TestCase):
def test_positional_encoding_shape(self):
# 定义参数
d_model = 512
max_len = 1024
# 初始化PositionalEncoding
pe = PositionalEncoding(d_model=d_model, max_len=max_len)
# 检查pe buffer的形状
self.assertEqual(pe.pe.shape, (max_len, 1, d_model))
def test_positional_encoding_values(self):
d_model = 6
max_len = 10
pe = PositionalEncoding(d_model=d_model, max_len=max_len)
# 检查正弦和余弦交替填充
position = torch.arange(0, max_len).float().unsqueeze(1) # [max_len, 1]
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(torch.tensor(10000.0)) / d_model))
expected_pe = torch.zeros(max_len, d_model)
expected_pe[:, 0::2] = torch.sin(position * div_term)
expected_pe[:, 1::2] = torch.cos(position * div_term)
# 检查生成的pe和计算的expected_pe是否接近
self.assertTrue(torch.allclose(pe.pe.squeeze(1), expected_pe, atol=1e-6))
def test_forward_adds_positional_encoding(self):
d_model = 512
seq_len = 20
batch_size = 2
pe = PositionalEncoding(d_model=d_model, max_len=1024)
# 关闭 dropout, dropout 具有随机性
pe.eval()
# 创建一个输入张量
x = torch.zeros(seq_len, batch_size, d_model)
# 获取经过位置编码的输出
x_encoded = pe(x)
# 检查位置编码是否已添加到输入中
self.assertTrue(torch.allclose(x_encoded, x + pe.pe[:seq_len, :, :], atol=1e-6))
def test_dropout_effect(self):
d_model = 512
max_len = 1024
dropout = 0.5
pe = PositionalEncoding(d_model=d_model, dropout=dropout, max_len=max_len)
# 确保 dropout 应用在 forward 方法中
with torch.no_grad():
pe.eval() # 关闭 dropout
x = torch.zeros(20, 2, d_model)
x_encoded_no_dropout = pe(x)
pe.train() # 启用 dropout
x_encoded_with_dropout = pe(x)
# 确保在 dropout 启用的情况下,编码后有变化
self.assertFalse(torch.equal(x_encoded_no_dropout, x_encoded_with_dropout))
if __name__ == '__main__':
unittest.main()
Feed Forward Neural Network
在Transformer中, Encoder或者Decoder每个Block都需要用一个前馈神经网络来添加非线性:
$$ FFN(x) = ReLU(xW_1+b_1)W_2+b_2 $$
class FeedForwardNetwork(nn.Module):
"""
Using nn.Cov1d replace nn.Linear to implements Fn
"""
def __init__(self, d_model=512, d_ff=2048, p_drop=.1):
super(FeedForwardNetwork, self).__init__()
# self.ff1 = nn.Linear(d_model, d_ff)
# self.ff2 = nn.Linear(d_ff, d_model)
self.ff1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.ff2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=p_drop)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, x):
# x: [batch, seq_len, d_model]
residual = x
x = x.transpose(1, 2) # [batch, d_model, seq_len]
x = self.ff1(x)
x = self.relu(x)
x = self.ff2(x)
x = x.transpose(1, 2) # [batch, seq_len, d_model]
return self.layer_norm(residual + x)
为什么需要transpose
在这个 FeedForwardNetwork 实现中,x = x.transpose(1, 2) 的主要目的是适应 nn.Conv1d 层的输入格式要求。
nn.Conv1d 的输入维度要求是 [batch, channels, seq_len],其中 channels 表示输入特征的维度,而 seq_len 表示序列长度。因此,输入 x 的形状 [batch, seq_len, d_model] 需要在第 1 和第 2 个维度之间进行转置,变为 [batch, d_model, seq_len],才能让 Conv1d 层按照我们期望的方式处理特征维度 d_model。
使用 nn.Conv1d 替代 nn.Linear 的原因
选择 nn.Conv1d 主要是因为 Conv1d 在处理数据时具有更高的并行计算效率,特别是在 GPU 上。使用 kernel_size=1 的 Conv1d 等价于 Linear 操作的作用,可以理解为在每个时间步上执行相同的全连接层操作。
用两个 Conv1d 实现一个隐藏层的前馈网络
在一个前馈网络中,通常有一个线性变换(输入层到隐藏层)和一个非线性激活(比如 ReLU),然后再接一个线性变换(隐藏层到输出层)。因此,一个简单的前馈网络可以通过以下两步实现:
- 用第一个
Conv1d将输入特征维度d_model转换为隐藏层的维度d_ff,并应用非线性激活。 - 用第二个
Conv1d将隐藏层的维度d_ff转换回输出特征维度d_model。
这个实现方式完全等价于使用 Linear 层的一个隐藏层网络,因为 Conv1d 这里充当的角色就是逐特征位置的线性变换,不涉及相邻位置的卷积操作。
当 Conv1d 的卷积核大小为 1 时,它与 Linear 层等价,因此可以用两个 Conv1d 实现一个有单隐藏层的前馈神经网络
Multi - Head Attention
多头注意力能够决定缩放点积注意力的输入大小. 作为一个子层, 其中的Residual Connection和Layer Norm是必须的.
多头注意力是多个不同的头来获取不同的特征, 类似于多个卷积核所达到的效果. 在计算完后通过一个Linear调整大小:
$$ MultiHead(Q,K,V)=Concat(head_1, head_2, \dots,head_h)W^o \newline where \quad head_i = Attention(QW_i^Q, kW_i^K, VW_i^V) $$
多头注意力在Encoder和Decoder中的使用略有区别, 主要区别在于Mask的不同. 我们前面已经实现了两种Mask函数, 在这里会用到.
多头注意力实际上不是通过弄出很多大小相同的矩阵然后相乘来实现的, 只需要合并到一个矩阵进行计算:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model=512, n_heads=8, d_k=64, d_v=64):
super(MultiHeadAttention, self).__init__()
self.n_heads = n_heads
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(d_v * n_heads, d_model, bias=False)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, input_Q, input_K, input_V, attn_mask):
"""
:param input_Q: [batch, len_q, d_model]
:param input_k: [batch, len_k d_model]
:param input_v: [batch, len_v, d_model]
:param attn_mask: [batch, len_q, len_q]
"""
residual, batch = input_Q, input_Q.size(0)
# [batch, len_q, d_model] -> matual W_Q -> [batch, len_q, d_q * n_heads] -> view -> [batch, len_q, n_heads, d_k] -> transpose -> [batch, n_heads, len_q, d_k]
Q = self.W_Q(input_Q).view(batch, -1, self.n_heads, self.d_k).transpose(1, 2) # [batch, n_heads, len_q, d_k]
K = self.W_K(input_K).view(batch, -1, self.n_heads, self.d_k).transpose(1, 2) # [batch, n_heads, len_k, d_k]
V = self.W_V(input_V).view(batch, -1, self.n_heads, self.d_v).transpose(1, 2) # [batch, n_heads, len_v, d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1, self.n_heads, 1, 1) # [batch, seq_len, seq_len] -> [batch, n_heads, seq_len, seq_len]
# prob: [batch, n_heads, len_q, d_v], attn: [batch, n_heads, len_q, len_k]
prob, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
prob = prob.transpose(1, 2).contiguous() # [batch, len_q, n_heads, d_v]
prob = prob.view(batch, -1, self.n_heads * self.d_v).contiguous() # [batch, len_q, n_heads * d_v]
output = self.fc(prob) # [batch, len_q, d_model]
return self.layer_norm(residual + output), att
如何通过一个矩阵实现多头注意力计算
在多头注意力机制中,通过将查询、键和值投影到多个头的子空间中,我们可以并行计算每个头的注意力。然而,具体实现中通常会通过一个矩阵操作来同时完成所有头的计算,而不是逐个计算每个头的注意力。以下是如何利用一个矩阵来实现多个头的注意力计算的详细解释。
-
线性变换的并行计算
- 多头注意力的每个头都需要独立的
Q、K和V,因此,为了效率,每个输入(Q、K、V)会通过一个大的线性变换来同时计算所有头的特征向量。 - 例如,假设模型的输入维度为
d_model,而多头注意力包含n_heads个头,每个头的d_k和d_v为特征维度。为了计算多头的Q,我们定义了一个形状为[d_model, d_k * n_heads]的矩阵W_Q:self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
input_Q的形状为[batch, len_q, d_model],经过W_Q变换后得到[batch, len_q, d_k * n_heads]。这样,多个头的查询向量可以一次性计算完毕,而不需要单独计算每个头。
- 多头注意力的每个头都需要独立的
-
拆分和调整形状
-
接下来,将
Q的输出形状[batch, len_q, d_k * n_heads]重新调整为[batch, len_q, n_heads, d_k],以便区分不同的头。这一步通常通过view和transpose实现:python 复制代码 Q = self.W_Q(input_Q).view(batch, -1, self.n_heads, self.d_k).transpose(1, 2) # [batch, n_heads, len_q, d_k] -
transpose(1, 2)是为了让n_heads维度在第 2 维,以便在后续计算中并行处理每个头。
-
-
并行计算注意力得分
-
通过上述步骤得到
Q,K,V后,接下来计算缩放点积注意力。对于每个头的Q、K和V都有形状[batch, n_heads, len_q, d_k]和[batch, n_heads, len_k, d_k]。 -
缩放点积注意力公式为:
$$ Attention = softmax(\frac{QK^T}{\sqrt{d_k}})V $$
-
由于
Q和K以及V都已经包含了所有头的信息,通过一次矩阵乘法Q @ K^T可以并行计算每个头的注意力权重。具体操作如下:attn_weights = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k) -
attn_weights的形状为[batch, n_heads, len_q, len_k],每一个头的注意力分数都被包含在其中。
-
-
应用注意力权重
-
接下来对每个头的
V应用注意力权重:attn_output = torch.matmul(attn_weights, V) # [batch, n_heads, len_q, d_v]
-
-
重组多头输出
- 最后,将所有头的输出拼接回一个整体。通过
transpose和view,将attn_output的形状[batch, n_heads, len_q, d_v]转换为[batch, len_q, n_heads * d_v],再用全连接层self.fc将多头的拼接输出映射回d_model维度。
- 最后,将所有头的输出拼接回一个整体。通过
通过这种方式,整个多头注意力计算可以高效并行地处理多个头,而不需要逐头地分别计算。
Scaled DotProduct Attention
Tranformer中非常重要的概念, 缩放点积注意力, 公式如下:
$$ Attention = softmax(\frac{QK^T}{\sqrt{d_k}})V $$
class ScaledDotProductAttention(nn.Module):
def __init__(self, d_k=64):
super(ScaledDotProductAttention, self).__init__()
self.d_k = d_k
def forward(self, Q, K, V, attn_mask):
"""
:param Q: [batch, n_heads, len_q, d_k]
:param K: [batch, n_heads, len_k, d_k]
:param V: [batch, n_heads, len_v, d_v]
:param attn_mask: [batch, n_heads, seq_len, seq_len]
"""
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(self.d_k) # [batch, n_heads, len_q, len_k]
scores.masked_fill_(attn_mask, -1e9)
attn = nn.Softmax(dim=-1)(scores) # [batch, n_heads, len_q, len_k]
prob = torch.matmul(attn, V) # [batch, n_heads, len_q, d_v]
return prob, attn
- 缩放因子
np.sqrt(self.d_k)是 Transformer 注意力机制中的重要一步,它通过对维度开平方来稳定梯度。 - 使用掩码填充
1e9是为了确保在Softmax后不关注某些位置。需要注意attn_mask的形状和scores匹配,否则会导致广播错误。
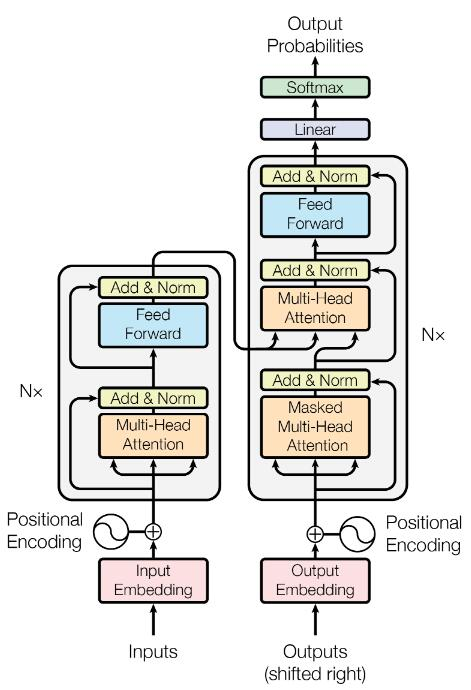
Encoder and Decoder
根据Transformer的结构图,Encoder和Decoder有多个相同层堆叠而成,每层包含多头注意力和FFN以及对应的残差连接和LayerNorm。
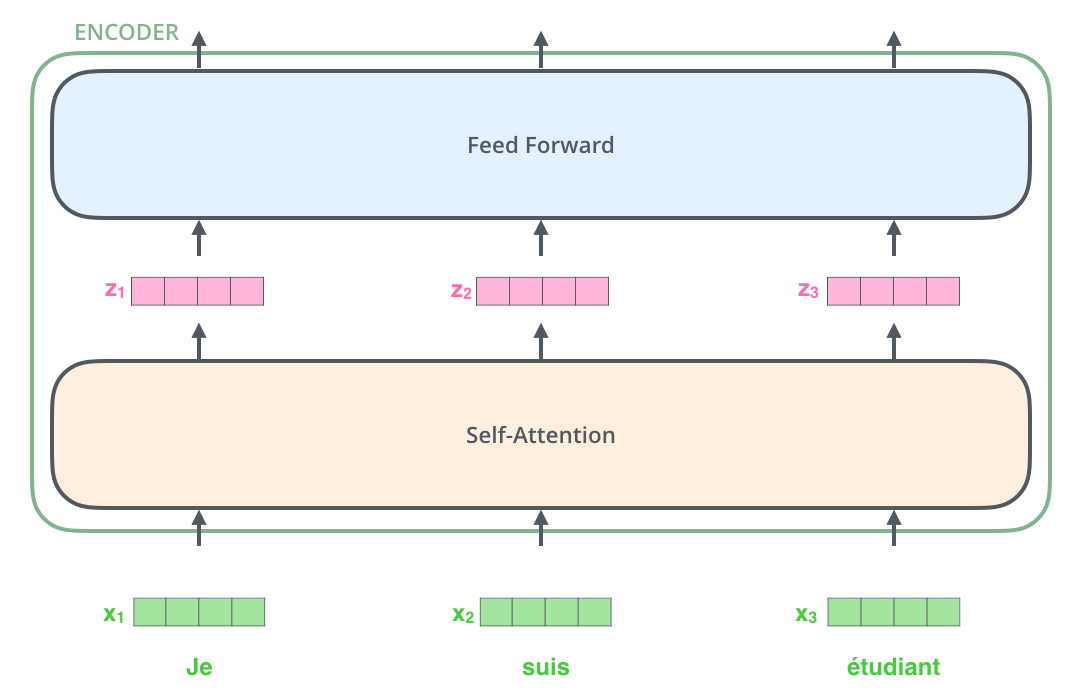
Encoder
先定义Encoder Layer,输入为encoder_input和encoder_pad_mask ,返回encode_output维度与encoder_input相同,作为下一层的输入。
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.encoder_self_attn = MultiHeadAttention()
self.ffn = FeedForwardNetwork()
def forward(self, encoder_input, encoder_pad_mask):
"""
:param encoder_input: [batch, source_len, d_model]
:param encoder_pad_mask: [batch, source_len, source_len]
:return: encoder_output: [batch, source_len, d_model], attn: [batch, n_heads, source_len, source_len]
"""
encoder_output, attn = self.encoder_self_attn(encoder_input, encoder_input, encoder_input, encoder_pad_mask)
encoder_output = self.ffn(encoder_output) # [batch, source_len, d_model]
return encoder_output, attn
然后定义了一个完整的 Transformer 编码器模块(Encoder)。这是一个堆叠多个 EncoderLayer 的容器模块,主要用于从输入序列中提取深层次的特征表示。
class Encoder(nn.Module):
def __init__(self, d_model=512, n_layers=6, source_vocab_size=None):
super(Encoder, self).__init__()
self.source_embedding = nn.Embedding(source_vocab_size, d_model)
self.position_embedding = PositionalEncoding(d_model)
self.layers = nn.ModuleList([EncoderLayer() for layer in range(n_layers)])
def forward(self, encoder_input):
# encoder_input: [batch, source_len]
encoder_output = self.source_embedding(encoder_input) # [batch, source_len, d_model]
encoder_output = self.position_embedding(encoder_output.transpose(0, 1)).transpose(0, 1) # [batch, source_len, d_model]
encoder_self_attn_mask = get_attn_pad_mask(encoder_input, encoder_input) # [batch, source_len, source_len]
encoder_self_attns = []
for layer in self.layers:
# encoder_output: [batch, source_len, d_model]
# encoder_self_attn: [batch, n_heads, source_len, source_len]
encoder_output, encoder_self_attn = layer(encoder_output, encoder_self_attn_mask)
encoder_self_attns.append(encoder_self_attn)
return encoder_output, encoder_self_attns
encoder_output:编码器的最终输出,形状为 [batch, source_len, d_model],表示输入序列的深层次表示,供解码器或其他模块使用。
encoder_self_attns:所有编码器层的自注意力权重,形状为 [n_layers, batch, n_heads, source_len, source_len]。可用于可视化或解释模型关注的模式。
Decoder
Decoder与Encoder差别不大,只是每层增加了Cross Attention。
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.decoder_self_attn = MultiHeadAttention()
self.encoder_decoder_attn = MultiHeadAttention()
self.ffn = FeedForwardNetwork()
def forward(self, decoder_input, encoder_output, decoder_self_mask, decoder_encoder_mask):
"""
:param decoder_input: [batch, target_len, d_model]
:param encoder_output: [batch, source_len, d_model]
:param decoder_self_mask: [batch, target_len, target_len]
:param decoder_encoder_mask: [batch, target_len, target_len]
"""
# masked mutlihead attention
# Q, K, V all from decoder it self
# decoder_output: [batch, target_len, d_model]
# decoder_self_attn: [batch, n_heads, target_len, target_len]
decoder_output, decoder_self_attn = self.decoder_self_attn(decoder_input, decoder_input, decoder_input, decoder_self_mask)
# Q from decoder, K, V from encoder
# decoder_output: [batch, target_len, d_model]
# decoder_encoder_attn: [batch, n_heads, target_len, source_len]
decoder_output, decoder_encoder_attn = self.encoder_decoder_attn(decoder_output, encoder_output, encoder_output, decoder_encoder_mask)
decoder_output = self.ffn(decoder_output) # [batch, target_len, d_model]
return decoder_output, decoder_self_attn, decoder_encoder_attn
同时为了避免解码器看到未来的“答案”,需要额外的Mask。
class Decoder(nn.Module):
def __init__(self, d_model=512, n_layers=6, target_vocab_size=None):
super(Decoder, self).__init__()
self.target_embedding = nn.Embedding(target_vocab_size, d_model)
self.position_embedding = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for layer in range(n_layers)])
def forward(self, decoder_input, encoder_input, encoder_output):
"""
:param decoder_input: [batch, target_len]
:param encoder_input: [batch, source_len]
:param encoder_output: [batch, source_len, d_model]
"""
decoder_output = self.target_embedding(decoder_input) # [batch, target_len, d_model]
decoder_output = self.position_embedding(decoder_output.transpose(0, 1)).transpose(0, 1) # [batch, target_len, d_model]
decoder_self_attn_mask = get_attn_pad_mask(decoder_input, decoder_input) # [batch, target_len, target_len]
decoder_subsequent_mask = get_attn_subsequent_mask(decoder_input) # [batch, target_len, target_len]
decoder_encoder_attn_mask = get_attn_pad_mask(decoder_input, encoder_input) # [batch, target_len, source_len]
decoder_self_attn_mask = decoder_self_attn_mask.to(device)
decoder_subsequent_mask = decoder_subsequent_mask.to(device)
decoder_self_mask = torch.gt(decoder_self_attn_mask + decoder_subsequent_mask, 0)
decoder_self_attns = []
decoder_encoder_attn_attns = []
for layer in self.layers:
# decoder_output: [batch, target_len, d_model]
# decoder_self_attn: [batch, n_heads, target_len, target_len]
# decoder_encoder_attn: [batch, n_heads, target_len, source_len]
decoder_output, decoder_self_attn, decoder_encoder_attn = layer(decoder_output, encoder_output, decoder_self_mask, decoder_encoder_attn_mask)
decoder_self_attns.append(decoder_self_attn)
decoder_encoder_attn_attns.append(decoder_encoder_attn)
return decoder_output, decoder_self_attns, decoder_encoder_attn_attns
Corss Attention
在标准 Transformer 的解码器中,注意力机制包括:
- Decoder Self-Attention(解码器自注意力)
- Q,K,VQ, K, VQ,K,V 都来自解码器当前生成的目标序列。
- 用于捕捉目标序列中自身的上下文信息。
- 通常会应用掩码(Mask),确保解码器不能看到未来时间步的目标词。
- Cross Attention(跨注意力)
-
QQQ 来自解码器,K,V 来自编码器。
K,VK, V
-
用于将输入序列的特征动态地融合到目标序列中。
-
- Encoder Self-Attention(编码器自注意力)
- Q,K,VQ, K, VQ,K,V 都来自编码器的输入序列。
- 用于捕捉输入序列中的全局特征。
为什么Cross Attention的Q来自解码器,KV来自编码器?
因为跨注意力的任务是将编码器的输出与解码器的当前状态结合,生成与目标序列相关的上下文表示。
在 Transformer 的设计中,encoder_decoder_attn(即解码器中的跨注意力机制)之所以 Q 来自解码器,而 K 和 V 来自编码器,是因为跨注意力的任务是将编码器的输出与解码器的当前状态结合,生成与目标序列相关的上下文表示。以下是具体原因和背后的逻辑:
- 解码器的工作原理
解码器的主要任务是基于目标序列的部分输入(如已经生成的词)和编码器的输出,逐步生成目标序列。因此:
- 解码器需要在生成当前词时,关注输入序列中与当前上下文相关的信息。
- 解码器的跨注意力机制就是实现这一点的关键模块。
- 跨注意力机制中的 Q、K 和 V
-
Q (Query): 表示解码器当前生成位置的特征,即解码器的隐藏状态。它代表了当前解码器“想要问什么”。
-
K (Key): 表示编码器对输入序列的特征表示,代表了输入中“能被查询到的内容”。
-
V (Value): 与 K 对应,是输入序列特征的实际值信息,代表“被查询到的具体内容”。
在跨注意力中,解码器用其隐藏状态(Q)去查询编码器的特征(K 和 V),从而获取输入序列中与当前解码上下文最相关的信息。
-
为什么 Q 来自解码器,K 和 V 来自编码器?
这设计是基于解码器和编码器各自的角色:
- 编码器的角色:对输入序列进行编码,提取输入的语义特征,生成一组固定表示(K 和 V)。这些特征表示输入序列的全部信息。
- 解码器的角色:根据当前生成的目标序列片段和输入序列的特征,生成新的目标词。因此,它需要用自己的隐藏状态(Q)去关注编码器的输出(K 和 V)。
通过这种设计:
- 解码器的每个时间步可以根据编码器生成的全局特征,关注到输入序列中最相关的部分。
- 输入序列和目标序列可以动态交互,从而实现更好的翻译或生成效果。
Transformer
标准 Transformer 模型的三个核心部分:编码器(Encoder)、解码器(Decoder)以及投影层(Projection),并将其完整地串联在一起实现前向传播。
class Transformer(nn.Module):
def __init__(self, d_model=512, source_vocab_size=1024, target_vocab_size=1024):
super(Transformer, self).__init__()
self.encoder = Encoder(source_vocab_size=source_vocab_size)
self.decoder = Decoder(target_vocab_size=target_vocab_size)
self.projection = nn.Linear(d_model, target_vocab_size, bias=False)
def forward(self, encoder_input, decoder_input):
"""
:param encoder_input: [batch, source_len]
:param decoder_input: [batch, target_len]
"""
# encoder_output: [batch, source_len, d_model], encoder_self_attns: [n_layers, batch, n_heads, source_len, source_len]
encoder_output, encoder_self_attns = self.encoder(encoder_input)
# decoder_output: [batch, target_len, d_model]
# decoder_self_attns: [n_layers, batch, n_heads, target_len, target_len]
decoder_output, decoder_self_attns, decoder_encoder_attns = self.decoder(decoder_input, encoder_input, encoder_output)
decoder_logits = self.projection(decoder_output) # [batch, target_len, target_vocab_size]
return decoder_logits.view(-1, decoder_logits.size(-1)), encoder_self_attns, decoder_self_attns, decoder_encoder_attns
Training
class Seq2SeqDataset(Data.Dataset):
def __init__(self, enocder_input, decoder_input, decoder_output):
super(Seq2SeqDataset, self).__init__()
self.enocder_input = enocder_input
self.decoder_input = decoder_input
self.decoder_output = decoder_output
def __len__(self):
return self.enocder_input.shape[0]
def __getitem__(self, idx):
return self.enocder_input[idx], self.decoder_input[idx], self.decoder_output[idx]
sentences = [
# enc_input dec_input dec_output
['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],
['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E']
]
# Padding Should be Zero
source_vocab = {'P': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4, 'cola': 5}
source_vocab_size = len(source_vocab)
target_vocab = {'P': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'coke': 5, 'S': 6, 'E': 7, '.': 8}
idx2word = {i: w for i, w in enumerate(target_vocab)}
target_vocab_size = len(target_vocab)
source_len = 5 # max length of input sequence
target_len = 6
batch_size = 8
epochs = 64
lr = 1e-4
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Transformer(source_vocab_size=source_vocab_size, target_vocab_size=target_vocab_size).to(device)
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(model.parameters(), lr=lr)
encoder_inputs, decoder_inputs, decoder_outputs = make_data(sentences, source_vocab, target_vocab)
dataset = Seq2SeqDataset(encoder_inputs, decoder_inputs, decoder_outputs)
dataloader = DataLoader(dataset=dataset, batch_size=batch_size, shuffle=True)
for epoch in range(epochs):
'''
encoder_input: [batch, source_len]
decoder_input: [batch, target_len]
decoder_ouput: [batch, target_len]
'''
for encoder_input, decoder_input, decoder_output in dataloader:
encoder_input = encoder_input.to(device)
decoder_input = decoder_input.to(device)
decoder_output = decoder_output.to(device)
output, encoder_attns, decoder_attns, decoder_encoder_attns = model(encoder_input, decoder_input)
loss = criterion(output, decoder_output.view(-1))
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()